

Fog and Edge Computing
At Digitize01 Ltd, we understand that Fog and Edge Computing are revolutionizing how data is processed, stored, and transmitted in today’s hyper-connected world. As businesses embrace the Internet of Things (IoT) and demand real-time processing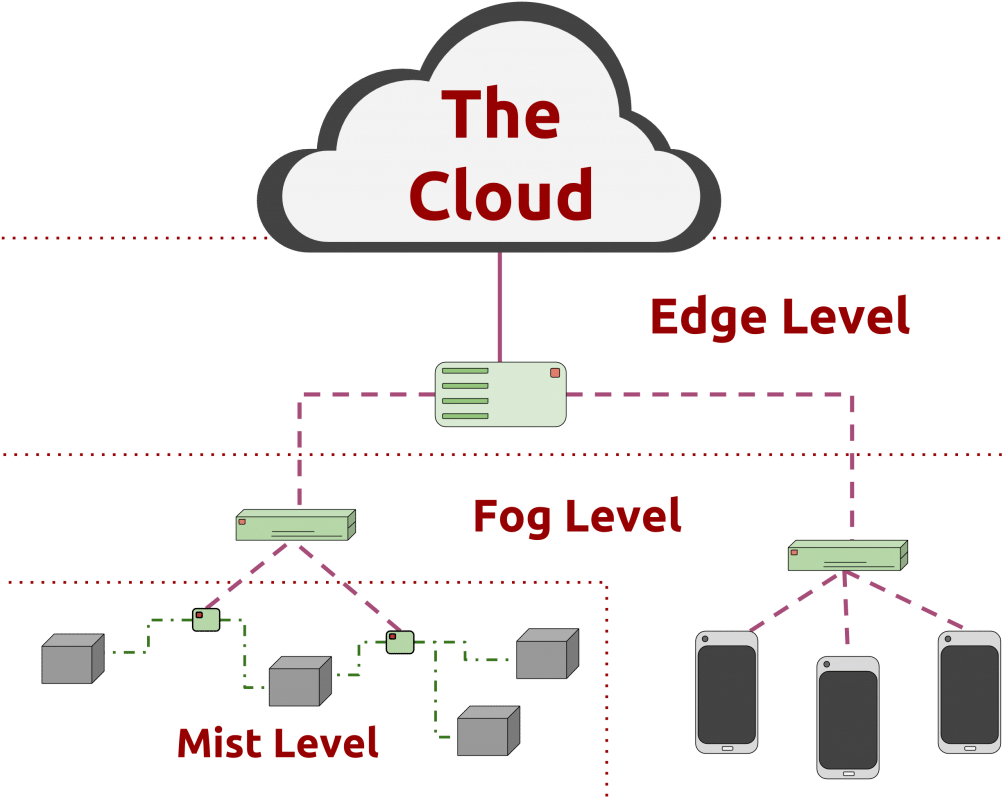 , Fog and Edge Computing provide a powerful solution by decentralizing data processing closer to the source of information. Through our Information Technology (IT) professional services, we help organizations implement these cutting-edge technologies to enhance performance, reduce latency, and optimize bandwidth usage.
, Fog and Edge Computing provide a powerful solution by decentralizing data processing closer to the source of information. Through our Information Technology (IT) professional services, we help organizations implement these cutting-edge technologies to enhance performance, reduce latency, and optimize bandwidth usage.
Whether it's deploying edge devices, managing distributed networks, or integrating real-time analytics, Digitize01 Ltd empowers businesses to harness the full potential of Fog and Edge Computing. This enables faster decision-making, improved operational efficiency, and greater scalability in the ever-evolving digital landscape. Let us guide your organization in adopting these technologies to stay ahead in the competitive market.
Select the language of your preference